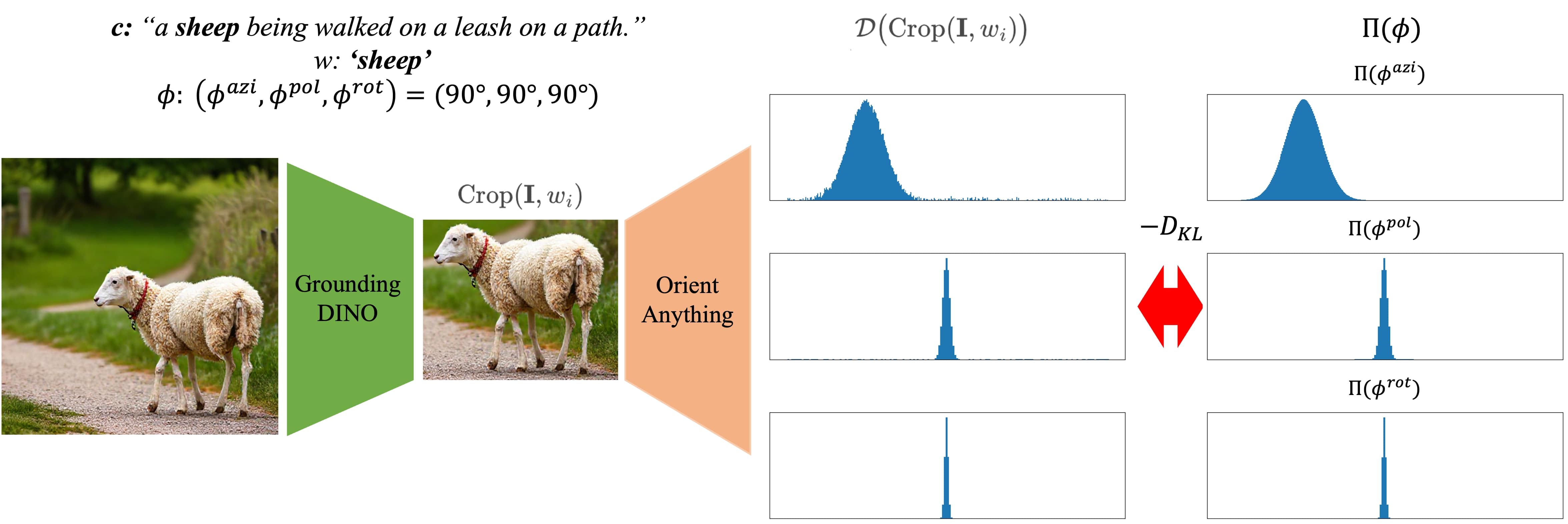
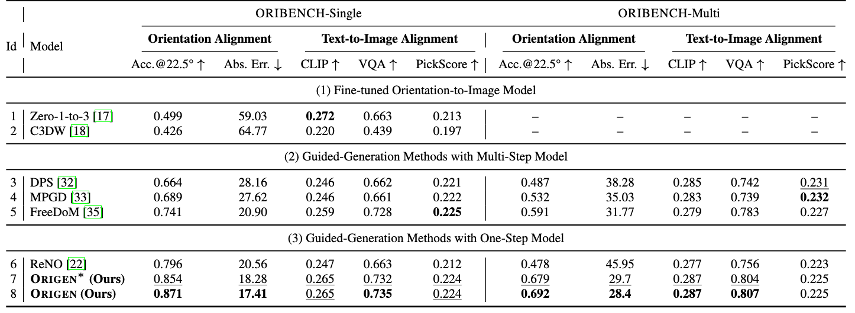
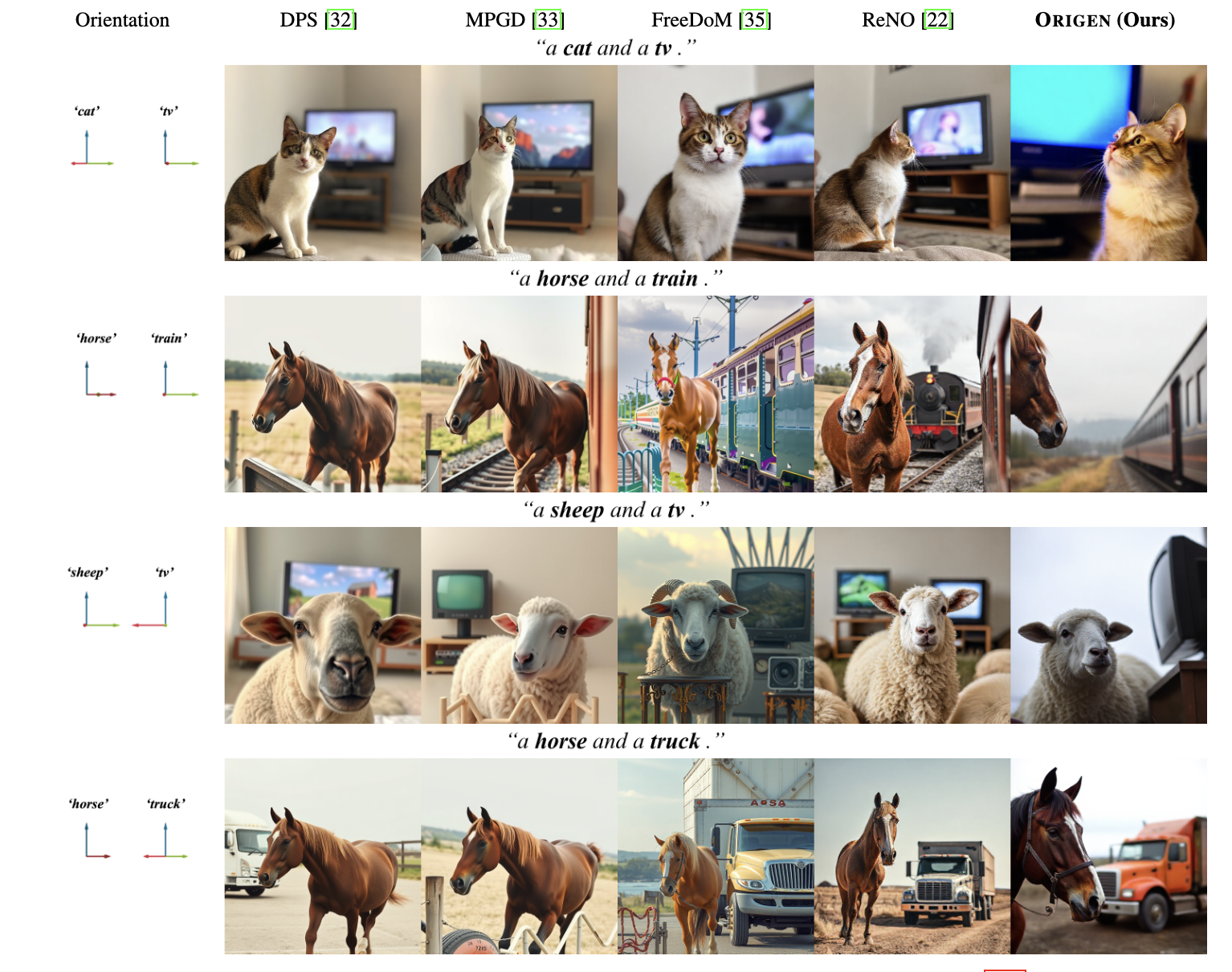
To formulate the Orientation Grounding problem as a reward maximization problem, we define the Orientation Grounding Reward for a given target 3D orientation \(\Pi(\phi_i)\) and image \(\mathbf{I}\) using negative KL divergence as follows:
\[ \mathcal{R}(\mathbf{I}) = - \frac{1}{N} \sum_{i=1}^{N} D_{\text{KL}}\Big(\mathcal{D}\big(\mathrm{Crop}(\mathbf{I}, w_i)\big) \,\Big\|\, \Pi(\phi_i)\Big). \]
Here, \(\mathcal{D}\) is the orientation estimation model (Orient-Anything), and \(\mathrm{Crop}(\mathbf{I}, w_i)\) extracts a centered object image using GroundingDINO, an open-set object detection model.
This reward function inherently supports multi-object orientation grounding by averaging rewards across multiple objects (N).
We introduce Reward-Guided Langevin Dynamics, to efficiently sample a latent representation \(\mathbf{x}\) from the optimal reward-aligned distribution. Unlike traditional gradient ascent, which may get stuck in local optima, this approach incorporates stochasticity, leading to the following simple discretized update rule:
\[ \mathbf{x}_{i+1} = \sqrt{1-\gamma}\, \mathbf{x}_i + \gamma\eta \nabla \hat{\mathcal{R}}(\mathbf{x}_i) + \sqrt{\gamma} \epsilon_{i}. \]
Note that for implementation, this requires only a single line of code, to add Gaussian noise \(\epsilon_i \sim \mathcal{N}(0, \mathbf{I})\) to the latent representation.
To further enhance convergence speed and performance, we introduce Reward-Adaptive Time Rescaling, modifying the Langevin process with a monitor function \(\mathcal{G}(\hat{\mathcal{R}}(\mathbf{x}))\) that dynamically adjusts the step size based on the reward:
\[ \mathbf{x}_{i+1} =\sqrt{1-\gamma(\mathbf{x}_i)}\mathbf{x}_i + \gamma(\mathbf{x}_i)\eta\,\nabla \hat{\mathcal{R}}(\mathbf{x}_i) + \frac{1}{2}\gamma(\mathbf{x}_i)\nabla\log \mathcal{G}(\hat{\mathcal{R}}(\mathbf{x}_i)) + \sqrt{\gamma(\mathbf{x}_i)}\,\epsilon_i. \]